





Вывод записей в случайном порядке
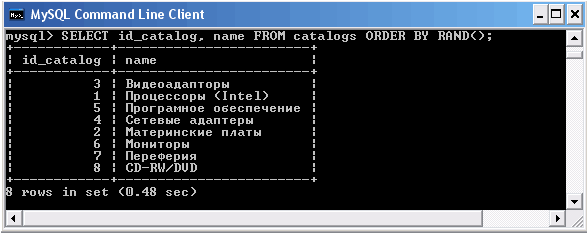
Для вывода записей в случайном порядке используется конструкция ORDER BY RAND(). Рассмотрим пример, где демонстрируется вывод содержимого таблицы catalogs в случайном порядке.
Вывод содержимого таблицы с случайном порядке
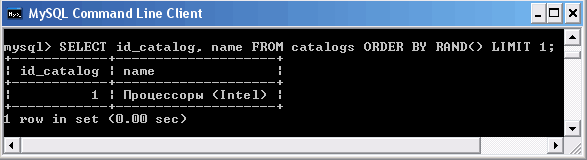
Если требуется вывести лишь одну случайную запись, используется конструкция LIMIT 1.
Вывод одной случайной записи
Ограничение выборки
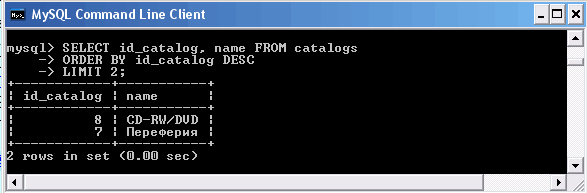
Результат выборки может содержать сотни и тысячи записей. Их вывод и обработка занимают значительное время и серьезно загружают сервер базы данных, поэтому информацию часто разбивают на страницы и предоставляют ее пользователю порциями. Извлечение только части запроса требует меньше времени и вычислений, кроме того, пользователю часто бывает достаточно просмотреть первые несколько записей. Постраничная навигация используется при помощи ключевого слова LIMIT, за которым следует количество записей, выводимых за один раз. Рассмотрим пример, где извлекаются первые две записи таблицы catalogs, при этом осуществляется их обратная сортировка по полю id_catalog.
Использование ключевого слова LIMIT
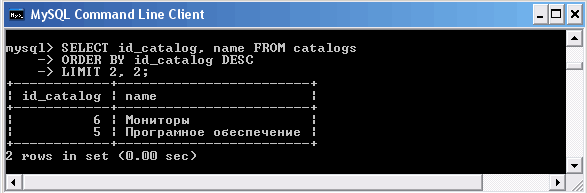
Для того, чтобы извлечь следующие две записи, используется ключевое слово LIMIT с двумя числами: первое указывает позицию, начиная с которой необходимо вернуть результат, а второе — количество извлекаемых записей.
Извлечение записей, начиная со второй позиции
Для извлечения следующих двух записей необходимо использовать конструкцию LIMIT 4, 2.
Вывод уникальных значений
Очень часто встает задача выбора из таблицы уникальных значений. Для этого воспользуемся таблицей tbl. Пусть требуется вывести все значения поля id_catalog.
Выборка значений поля id_catalog из таблицы tbl
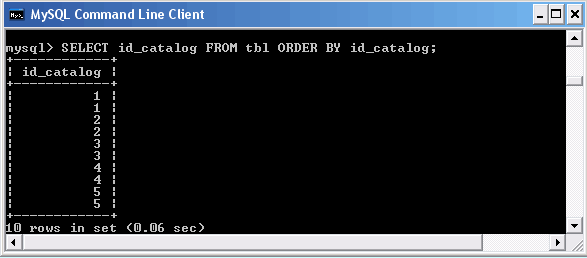
Как видно, результат не совсем удобен для восприятия. Было бы лучше, если бы запрос вернул уникальные значения столбца id_catalog. Для этого перед именем столбца можно использовать ключевое слово DISTINCT, которое предписывает MySQL извлекать только уникальные значения.
Примечание. Ключевое слово DISTINCT имеет синоним DISTINCTROW.
Выборка уникальных значений
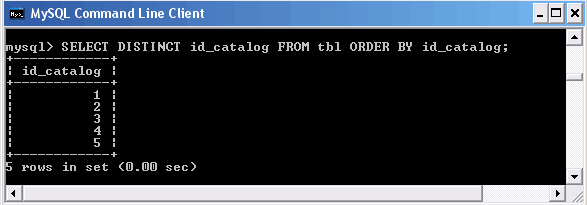
Результат запроса не имеет ни одного повторяющегося значения.
Для ключевого слова DISTINCT имеется противоположное слово ALL, которое предписывает извлечение всех значений столбца, в том числе и повторяющихся. Поскольку такое поведение установлено по умолчанию, ключевое слово ALL часто опускают.
Часто для извлечения уникальных записей прибегают также к конструкции GROUP BY, содержащей имя столбца, по которому группируется результат.
Примечание. Конструкция GROUP BY располагается в SELECT-запросе перед конструкциями ORDER BY и LIMIT.
Использование конструкции GROUP BY
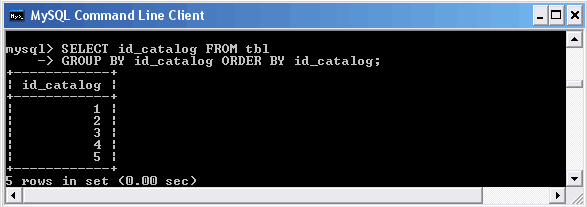
Объединение таблиц
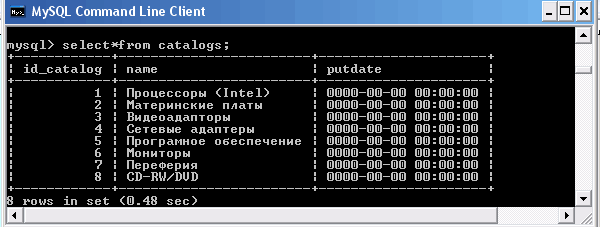
Как мы уже знаем, оператор SELECT возвращает результат в виде таблицы. Если формат результирующих таблиц (число, порядок следования и тип столбцов) совпадает, то возможно объединение результатов выполнения двух операторов SELECT в одну результирующую таблицу. Это достигается использованием оператора UNION. Для примера воспользуемся ранее созданными таблицами catalogs и tb3. Подгоним структуру таблицы tb3 под таблицу catalogs и заполним ее содержимым.
Таблица tb3
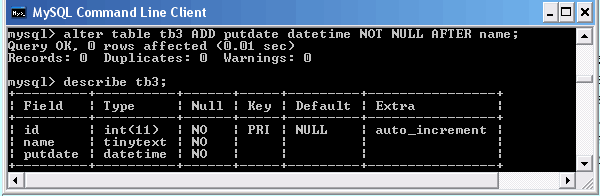
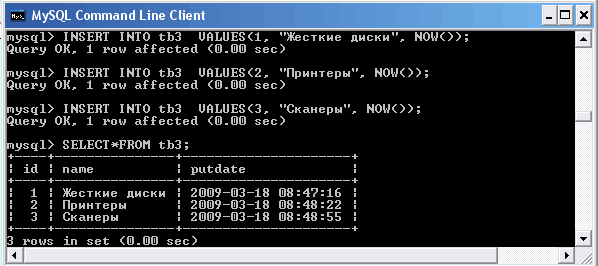
Таблица catalogs
Объединим результаты этих таблиц, соединив два запроса SELECT при помощи ключевого слова UNION.
Использование ключевого слова UNION
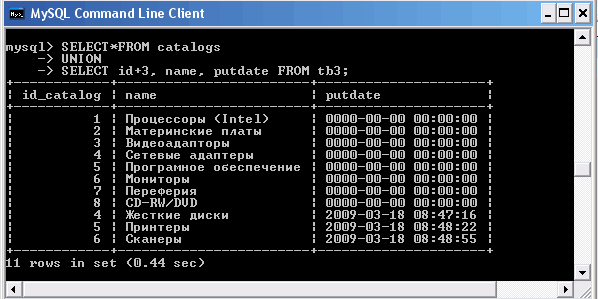
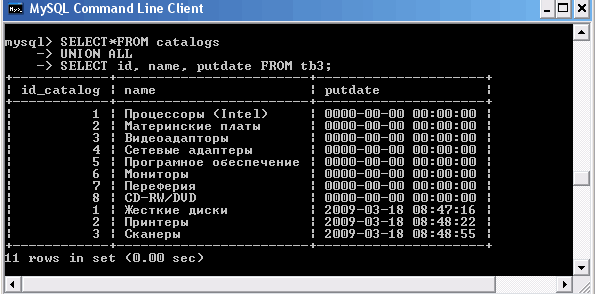
Во втором запросе SELECT, производящем выборку из таблицы tb3, к значению первичного ключа id добавляется значение 3, и таким образом, все значения в результирующей таблице становятся уникальными. Если результирующая таблица содержит повторяющиеся строки, СУБД MySQL автоматически отбрасывает дубликаты. Изменить поведение по умолчанию можно при помощи ключевого слова ALL, которое добавляется после оператора UNION. Использование оператора UNION ALL требует, чтобы возвращались все строки результирующих таблиц.
Использование ключевого слова UNION ALL
Комментарии(0)
Для добавления комментариев надо войти в систему и авторизоватьсяКомментирование статей доступно только для зарегистрированных пользователей:Зарегистрироваться